最近看google trends比较多,发现有一个特殊情况。
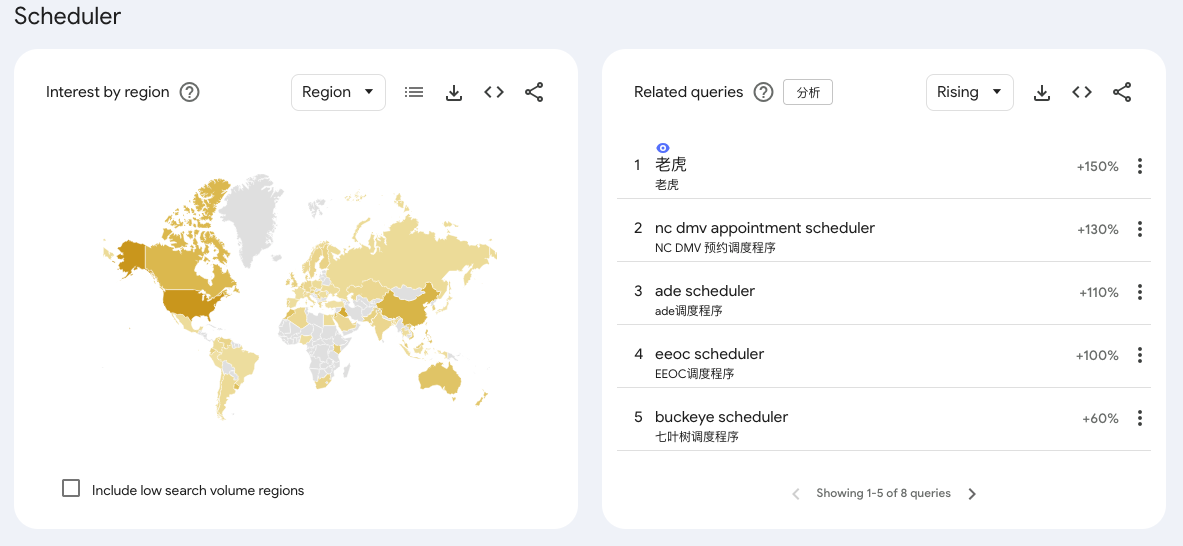
输入某一些词根的时候,在其related quires中会出现和这个词根毫不相关的词汇。例如:“老虎”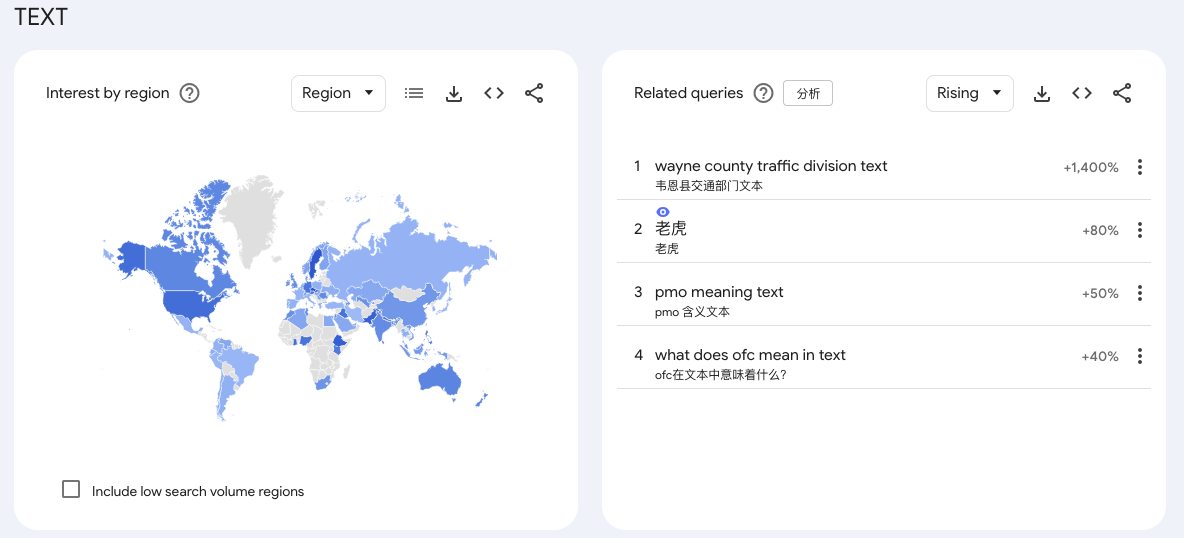
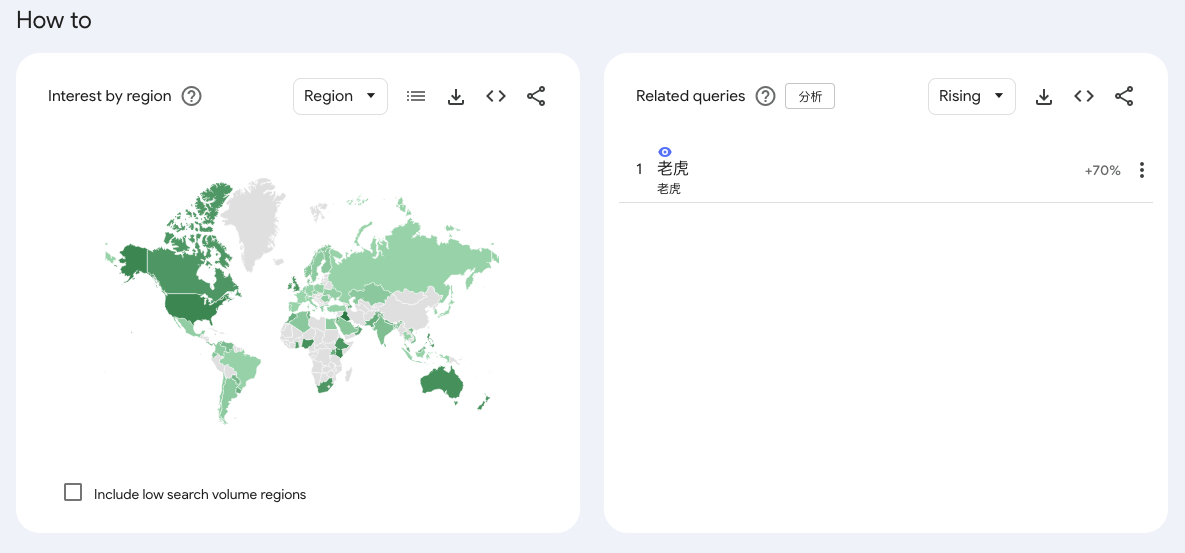
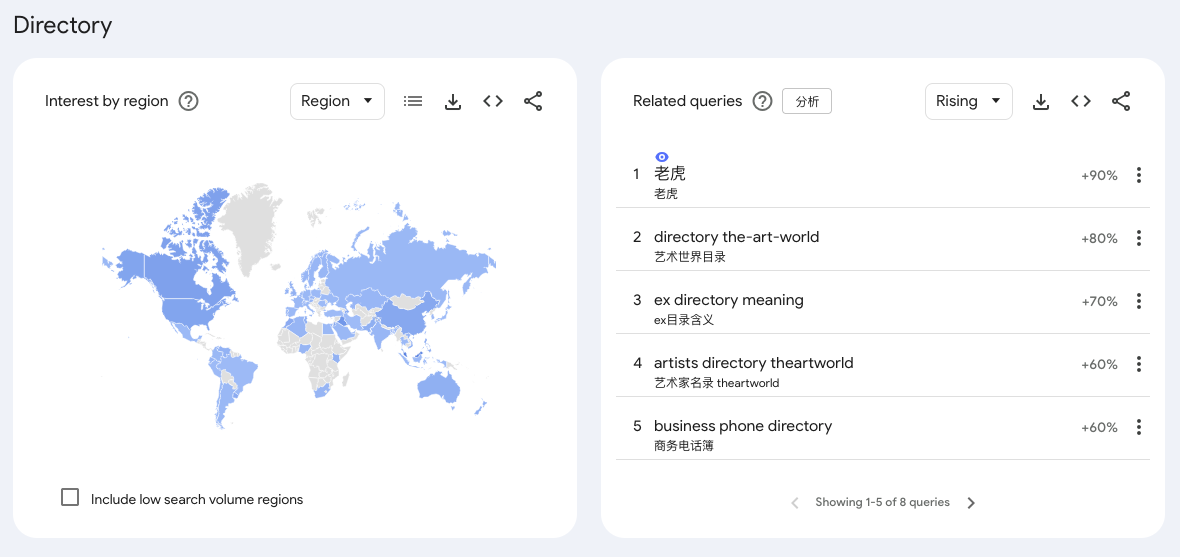
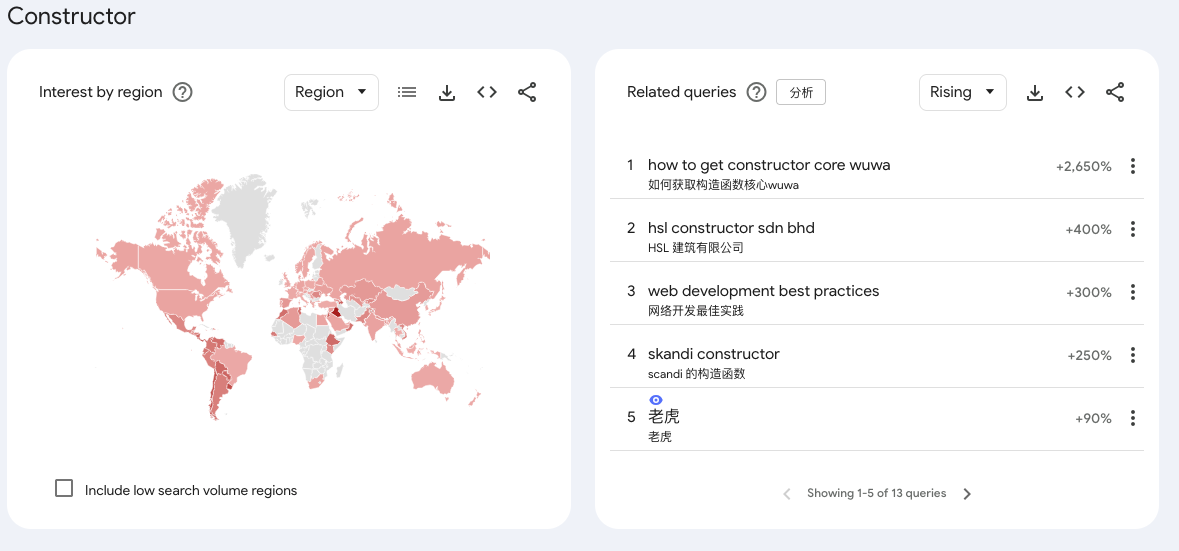
 经典的情况还有:lidl near me 这个词
经典的情况还有:lidl near me 这个词
这个情况十分诡异,所以我先找了AI进行询问:
Google Trends 的“相关查询(Related queries)”中出现看起来不相关的词汇(如“老虎”),通常是由以下几个原因造成的:
-
行为关联而非语义关联Google Trends 的算法主要基于用户行为的统计相关性,而不是词语本身的含义。Rising 模式的算法本质:低基数 + 高百分比 = 噪声 Rising ;显示的是某一时段相对上一时段的搜索增长百分比。Rising searches 是与你输入的关键词在同一会话中被搜索、且在所选时间段内增长最显著的词。关键点在于"同一会话(same search session)"——只要有用户在同一个 session 里既搜了 "TEXT" 又搜了 "老虎",就会被算入。这个情况下,共同搜索: 如果大量用户在同一个搜索会话中先后搜索了“TEXT”和“老虎”,系统就会认为两者具有相关性。搜索习惯: 搜索“TEXT”的人可能也在关注某些特定的应用或平台。例如,互联网券商老虎证券(Tiger Brokers)常被简称为“老虎”,其用户在查找交易相关的“Text message(文本消息)”通知或验证码时,可能会产生这种数据上的重合 [1.4.10, 1.4.5]。
-
特定的品牌或应用名称“TEXT”一词非常广泛,可能指向特定的工具:TigerText(现名 TigerConnect): 这是一个非常知名的医疗级加密聊天应用。由于其名称中包含“Tiger”,当用户搜索“Text”相关话题时,该应用的活跃度波动可能导致“老虎”这个词在中文语境下被关联出来 [1.5.2, 1.5.4]。AI 与文本处理: 近期如 TigerGPT 等基于文本生成的 AI 工具(由老虎证券推出)在金融圈内讨论度较高,这也可能加强了“文本(Text)”与“老虎”的关联 [1.4.7]。
-
异常搜索活动 / 自动化搜索 Google 自己承认了这一点:在极少数情况下,Google Trends 也可能反映异常搜索活动,例如自动化搜索或可能与试图操纵搜索结果相关的查询。
-
多语言混合 session 中文用户的 Chrome session 里同时搜中文词(老虎)和英文技术词(Constructor、Directory、Schedule 都是编程词),Google 的协同搜索算法会把这种 session 内共现算成关联。考虑到你列举的词根里 Constructor、Directory、Schedule 都偏开发者向,这个解释在量级上是站得住脚的。
lidl near me 的问题恰恰相反——它搜索量极大、且持续在涨,反而成了一个"幽灵词"污染所有人的 keyword research。 具体原因有几层:
- Lidl 在美国和欧洲处于持续门店扩张期 Lidl 这几年在美国疯狂开店,欧洲老市场也在加门店。这意味着 "lidl near me" 在 Google 全站长期处于持续上涨状态——不是某个月暴涨,是常年都在 rising。这就导致它在任意时间窗口、任意 related queries 的 Rising 榜单里都"够格"出现。
- "Near me" 类 query 是 session 的"背景辐射" 这是关键洞察。普通用户一天内在 Google 搜很多东西:早上查个编程问题("how to..."),中午顺手搜 "lidl near me" 找午饭买菜,晚上又搜个动漫词。Google Trends 的 related queries 算法是基于 session 内共现的——Top 类是与你输入的关键词在同一搜索会话中被搜索最频繁的词。 Google Support 像 "lidl near me"、"weather"、"google translate"、"facebook" 这种日常高频生活类 query,在每一个用户的 session 里都可能出现。它们不是和某个特定 keyword 有真实语义关联,而是 session 时间维度上的"碰瓷"。
- 抽样偏差被放大 Google Trends 用的是抽样数据集而非完整数据集。当某个 query 的搜索量大到一定程度(lidl near me 在欧洲是 millions/month 级别),它在 Google 抽样的任何子集里都几乎必然出现。低搜索量的词根去找它的 rising related queries,相当于在小样本里捞数据,而 "lidl near me" 这种 ambient query 自带高出现概率,就被算法误判为"相关"。 Glimpse
- 商业高价值词容易被自动化流量污染 Google 表示会过滤操纵和垃圾数据,但如果它流行到一定程度仍可能出现。"near me" 类商业意图词是 SERP scraper、本地 SEO 工具、联盟营销刷量的重点目标。Lidl + near me 是非常典型的高 CPC、可货币化 query,自动化访问会进一步推高它的"全场出现频率"。 Fresh Egg Ltd
- Google Trends 自家筛掉的也会泄漏过来 Google 的抽样会包括从其他搜索产品(比如 related searches 或 autocomplete)中已经被移除的数据。也就是说有些在正式 SERP 里被反垃圾系统压制的查询,反而在 Trends 这边浮上来了。